
Ein sortierter Baum lässt sich mit der binären Suche schnell durchsuchen. Die Laufzeit verhält sich dabei logarithmisch zur Größe der Wertemenge (), da mit jedem Schritt die zu durchsuchenden Werte halbiert werden.
Der Binäre Suchbaum ist eine besondere Erweiterung des Binären Baums, die zu jedem Zeitpunkt sortiert ist.
Eine gute Visualisierung des BinarySearchTree findet sich auf der Website der University of San Francisco, besonders beim Löschen des Baumes kann sie diesen Artikel gut veranschaulichen: Visualisierung BST
Wann ist ein Binärer Baum sortiert?
- Die Wurzel des linken Teilbaum ist leer oder kleiner als die aktuelle Wurzel
- Die Wurzel des rechten Teilbaum ist leer oder größer als die aktuelle Wurzel
- linker und rechter Teilbaum sind sortiert
Sind diese Bedingungen erfüllt, befinden sich im linken Teilbaum eines Knotens alle Werte die kleiner, im rechten Teilbaum alle Werte die größer als der aktuelle Knoten sind.
So lässt sich ein rekursiver Algorithmus aufstellen, der einen BinarySearchTree auf seine Zulässigkeit überprüft:
boolean isSorted(BinarySearchTree<T> tree) {
if (tree.isEmpty()) { return true; }
if (
!tree.getLeftTree().isEmpty() &&
tree.getContent().isLess(tree.getLeftTree().getContent())
) { return false; }
if (
!tree.getRightTree().isEmpty() &&
tree.getRightTree().getContent().isLess(tree.getContent())
) {
return false;
}
return (
isSorted(tree.getLeftTree()) &&
isSorted(tree.getRightTree())
);
}
Wie wird die Sortierung gewährleistet?
Um den Baum durchgängig sortiert zu halten, werden Elemente beim Einfügen direkt richtig einsortiert. Beim Löschen eines Wertes wird so gelöscht, dass die Sortierung erhalten bleibt.
Einfügen
Im Suchbaum können neue Werte nur als Blätter angehangen werden. Dafür wird der Baum solange traviersiert, bis ein leerer Teilbaum gefunden wurde. Die Regeln für das Traversieren lauten:
- Ist der einzufügende Wert kleiner als der aktuelle Knoten, gehe links.
- Ist der einzufügende Wert kleiner als der aktuelle Knoten, gehe rechts.
- Sonst: Tue nichts, der Wert ist schon vorhanden.
An der dritten Regel lässt sich erkennen, dass ein Wert nicht mehrmals im Suchbaum vorhanden sein kann.
Wurde durch das Traversieren ein leerer Teilbaum ausfindig gemacht, wird der Wert dort eingefügt.
Entfernen
Das Löschen aus einem Binären Suchbaum gestaltet sich schwieriger. Wichtigste Regel ist: Nach einer Lösch-Operation muss der Suchbaum immer noch sortiert sein.
Nachdem man das zu löschende Element gefunden hat, können vier Fälle auftreten: Das zu löschende Element…
- … ist ein Blatt
- … hat nur einen Teilbaum
- … hat zwei Teilbäume
Im ersten Fall lässt sich das Blatt einfach löschen:
tree.setContent(null);
tree.setLeftTree(null);
tree.setRightTree(null);
Im zweiten Fall kann man den existierenden Teilbaum eine Ebene nach oben schieben:
BinarySearchTree<T> existingTree =
!tree.getLeftTree().isEmpty()
? tree.getLeftTree()
: tree.getRightTree();
tree.setContent(existingTree.getContent());
tree.setLeftTree(existingTree.getLeftTree());
tree.setRightTree(existingTree.getRightTree());
Im dritten und schwierigsten Fall muss ein Element aus den Teilbäumen gefunden werden, mit welchem man das zu löschende Element ersetzen kann, ohne die Sortierung zu zerstören.
Es gibt zwei Werte, die diese Anforderung erfüllen:
- das Maximum des linken Teilbaums
- das Minimum des rechten Teilbaums
Dieser Knoten lässt sich durch einen simplen Traversierungsalgorithmus finden:
BinarySearchTree<T> findMax(BinarySearchTree<T> tree) {
if (!tree.getRightTree().isEmpty()) {
return findMax(tree.getRightTree());
}
return tree;
}
Nun wird Knoten des zu löschenden Elements auf den so gefundenen Wert gesetzt und der gefundene Wert ebenfalls gelöscht.
BinarySearchTree<T> maxInLeftTree = findMax(tree.getLeftTree());
tree.setContent(maxInLeftTree.getContent());
maxInLeftTree.remove(maxInLeftTree.getContent());
Welche Probleme hat ein Binärer Suchbaum?
Neben einer logarithmische Suchlaufzeit und dynamischer Erweiterbarkeit bringt der Binäre Suchbaum allerdings auch Probleme mit sich:
Der kann Baum unbegrenzt in die Tiefe wachsen. Abhängig von der Eingabereihenfolge können dabei sogenannte entartete Bäume entstehen, die zwar Technisch als Binäre Bäume anzusehen sind, aber nicht ihre Vorteile bieten:
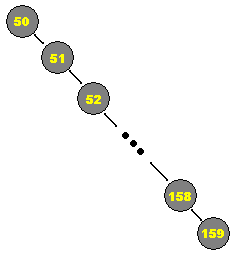
Diesen Baum nun zu sortieren hat die Laufzeit und kann nicht dynamisch geschehen.
Binäre Suche mag zwar im ersten Moment schnell wirken, ist es aber bei großen Datenmengen nicht: Ein Rechenbeispiel zeigt, dass das Suchen nach einem User in einer Datenbank mit 2,1 Milliarden Nutzern (siehe Facebook) in einem perfekt balancierten Binären Suchbaum 60ns dauert. Möchte man alle nun also über alle 2,1 Milliarden Nutzer iterieren, dauert dies schon 2,1 Minuten - zu lange für Facebook.
Diese Probleme möchte der B-Baum lösen.
B-Baum
Der B-Baum ist eine von Rudolf Bayer entwickelte Datenstruktur, die in jedem Knoten mehrere Werte hält.

Zwischen diesen Werten werden dann Pointer zu den Zweigen gespeichert. Besonders ist, dass die Anzahl der Werte pro Knoten beschränkt ist. Übersteigt einer der Knoten die maximal erlaubte Anzahl von Werten, so wandert dieser Wert eine Ebene nach oben. Die übrigen Werte des Knoten werden nun in zwei neue Zweige aufgeteilt.

Der B-Baum wächst mit zunehmender Anzahl an Werten also nicht nach unten, sondern nach oben. Dadurch, dass in einem Knoten mehrere Werte sind, bleibt der B-Baum sehr flach und kann schnell durchsucht werden. Deshalb wird er unter anderem in Datenbank-Systemen gerne eingesetzt, zuerst fand er seine Anwendung im System R von IBM.